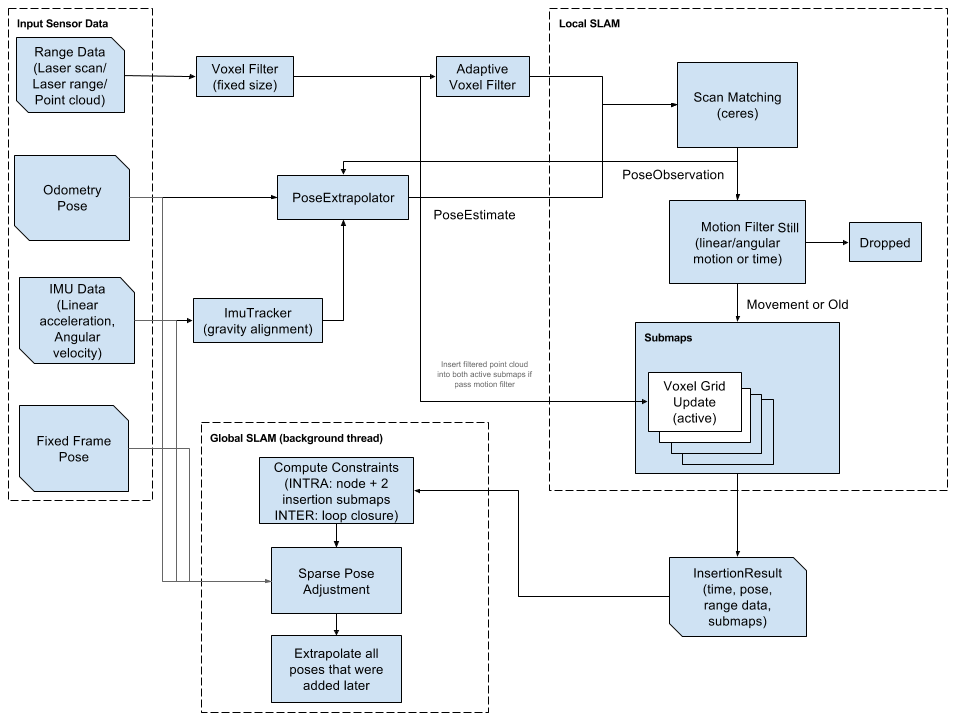
|
| https://github.com/team401/Vision-Tutorials/wiki/Yaw-and-Pitch |
In recent weeks, I have spent some time brushing up on as many types of Attitude and Heading Reference Systems (AHRS) as I can. I wanted to code them, and compare them in a meaningful way and eventually implement them on an Arduino. My initial goal has been to work with three types: The Madgwick Filter, an Extended Kalman Filter and an Unscented Kalman Filter. As of right now, I have each of them working and am able to play back a few different types of csv datasets. All of my code is on my
github.
I should note that I collected data from my phone, which is a Google Pixel, that holds a BMI160 IMU sensor with a 3 axis accelerometer, 3 axis gyroscope, 3 axis magnetometer, a barometer and a temperature sensor. I am sampling the data using an app called HyperIMU (available on the Google Play Store). As of right now, I have only integrated the gyroscope and the accelerometer and am working on the magnetometer updates.
All of my implementations are very simple models, that do not yet introduce the gyroscope bias as parameter in the filter. This will be added later, because it complicates the model. My states are the quaternion values: w, x, y, z and all operations are done in quaternion space in order to avoid the singularity when the pitch is at 90 degrees.
The Madgwick Filter
The Madgwick Filter is based on this
paper by Sebastian Madgwick. Remarkably, it is a very new algorithm, but has been widely used across many systems. The idea of this filter is to incorporate updates to the classic gyroscope integration via an optimization assumption. The initial update is to correct for drift in the pitch and roll directions by taking advantage of the direction of gravity from the accelerometers. Essentially, the algorithm forms an objective function between the gravitational vector rotated into the frame of the sensor and the acceleration vector in the frame of the sensor. The idea is that at all times, the acceleration is an approximation of the gravity, even though there may be some acceleration due to movement and noise. The optimization is solved with a gradient descent solution and is therefore, always attempting to correct any drift originating from the gyroscope in the gravity related directions.
Here is an image of the results of the Madgwick filter when applied to my phone spinning along the three axes. This is particular run is using the recommended beta gain value from the paper, however, I have found that setting it to between 0.04 and 0.2, allows it to converge faster and more accurately.
As you can see in the image, the prediction of roll, pitch and yaw works well. In the roll and pitch directions, you can see that the filter is slowly converging back to 0 degrees. If I increase the beta value, I can speed up that convergence, but it comes at the cost of factoring in any acceleration that is not due to gravity. To see the divergence, I decided to compare residual between the estimate and the measurement. What is interesting to see is what happens when we have actual movement of the phone and how it causes divergence in the filter values.
The Extended Kalman Filter
The EKF is the standard equation for most estimation problems and it fits well for the AHRS, as well. Essentially, the EKF is a typical Kalman filter that linearizes the prediction and update equations in order to estimate the uncertainty of each of the states. The uncertainty is used to weight measurement updates in order to shrink the overall error of the system. When the sensor is moving with extra acceleration, the gravity updates are far more damaging than they are in the Madgwick filter. In order to mitigate this problem, I decided to only apply updates when the change in acceleration along all three axes is less than a threshold. This way, we know that the phone is stationary during this period. In the future, I will work on a more robust way to find allowable update times.
Here is the results of the EKF. The Euler plot shows fast convergence back to 0 degrees in the pitch and roll after rotations. We can see a bit more noise in the solution than Madgwick Filter, but faster convergance. This is probably because the linearized function does not approximate the uncertainty distribution as well.
I have only plotted the residuals when I have done updates. As you can see, the residual is zero mean and has a nice error distribution after the updates. This means that the filter is doing its job.
The Unscented Kalman Filter
The UKF was a curious addition to this batch of algorithms. Typically, a UKF is used if there is an unclear distribution function. It works by creating a distribution from a few "Sigma Points", which are projections of the system states with a fraction of the noise added back in. This creates a pseudo space that approximates the distribution of the uncertainty of each state.
This image was very helpful in my understanding of the UKF. Basically, a proportion of the standard deviation of the uncertainty is added to each state and then either projected forward in time by the state transition matrix or rotated to the measurement frame.
 |
| https://github.com/rlabbe/Kalman-and-Bayesian-Filters-in-Python/blob/master/10-Unscented-Kalman-Filter.ipynb |
Here are the results of the UKF. Again, we are seeing good results in terms of convergence back to zero after large movements in pitch and roll. We also see that we have somewhat Gaussian Error in the residual.
Here are the histograms of the Roll and Pitch error. Both are very Gaussian and has almost exactly the same amount of mean and error as the EKF.
Now that I have this done, I have a few other things that I want to do to improve my results. These things include:
- Yaw correction via Magnetometer
- Gyroscope bias correction, also with the Magnetometer and possibly the Temperature Sensor
- Process and Measurement noise improvement via adaptive EKF
- Implementation in C for realtime estimation on Arduino